A Complete View of the South African Consumer: Part 1
This blog is the first in a series on how we built the ENS (Eighty20 National Segmentation), a comprehensive South African consumer profiling tool and segmentation.
Eighty20 provides access to a wide array of datasets describing the South African population. While each of these datasets has its own unique focus and provides many interesting insights, no single dataset provides a full picture of the South African consumer.
This got us thinking: How can we merge these different datasets to create a single master dataset with a more complete view of the South African population?
This is how we went about tackling the problem, combining the depth and breadth of insights available from the secondary and administrative datasets that Eighty20 provides to our clients.
Our first challenge was to be able to filter one dataset based on an attribute that originates from another dataset. For example, how could we observe the credit behaviour of people who are highly likely to be in LSM 10, when there is no indication of LSM in the credit bureau data?
While all these datasets are unique, there are certain key variables that can be found in almost all of them, such as age, income, gender, location, and marital status. We used a selection of demographic “overlap” variables to summarise the data in each dataset individually, and then joined the summaries from each dataset together.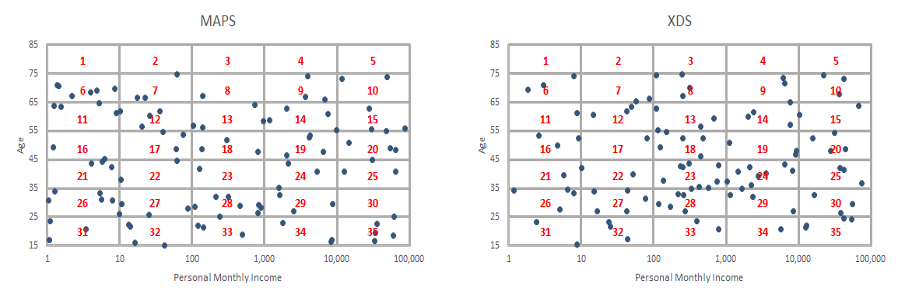
In the example plots above, each dot represents the age and income of an individual in each dataset. The grid shows how we can group these individuals into different age and income brackets. We can create summary statistics for each group, or box in the grid, based on the remaining fields in each dataset, and then join the summaries from the two datasets. This creates a new dataset of the South African population that combines data from the two original datasets.
For such a method to make sense, it is important that the overlap variables we choose are good predictors of the data we are trying to summarise. Otherwise, there is no reason to expect the summarised profiling data from one group to be different from that of another group. We noticed that many of these overlap variables are strongly predictive of other attributes of the individuals. For example, one would expect that someone who has passed retirement age is less likely to engage in digital activities, such as online shopping and social media. Similarly, one would expect someone with a high income to be more likely to shop at high-end retail and grocery brands.
We decided to test this more thoroughly by selecting important profiling fields (such as home ownership, cell phone use, etc.) and seeing how much the overlap variables (both the variable itself and the selected bands for that variable if it was discrete) influenced what we saw for the given field. We then chose the overlap variables that were the most reliable predictors for all selected fields.
Overcoming sampling error
With our overlap variables chosen, we had essentially broken the South African population into a number of “microsegments” consisting of all the possible combinations of our chosen overlap variables. Looking at the results for each of these microsegments, we noticed the first major problem with this approach.
For some of the microsegments, we had a lot of observations in a given dataset, and therefore could rely on the summary statistics for these microsegments. But for other microsegments, we had a very small sample size. In these cases, there was the potential for sampling error to make the summary statistics unreliable. We wanted the uniqueness of different microsegments to be maintained if we had enough observations to trust the results, but we also wanted to have reliable statistics for each of them.
So we built a model that adjusted the statistics of each microsegment to be more in line with those around it. The more observations the microsegment had, the smaller the adjustments made by the model. As a result, microsegments with large samples were not adjusted much – they would maintain their uniqueness should they have any. Meanwhile, microsegments with minimal observations (a small sample size) would essentially borrow information from microsegments surrounding them (e.g. other microsegments that refer to people in their same age group), so that their estimated statistics would be more reliable.
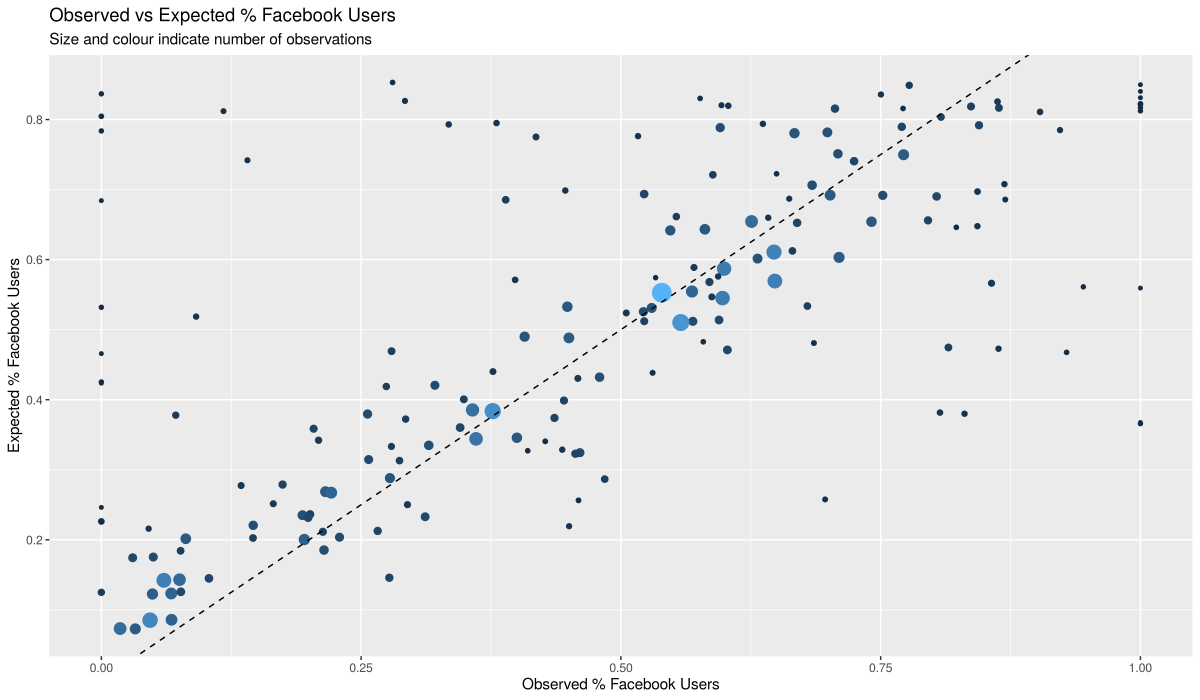
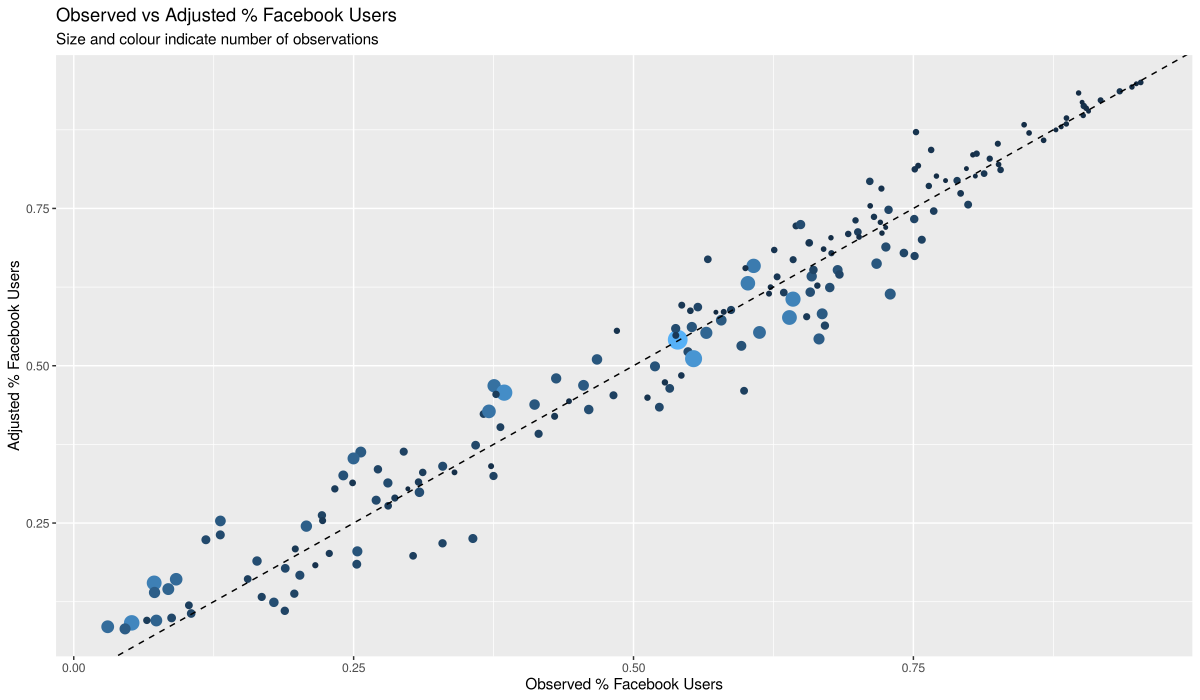
The above graphs show the summary statistic for Facebook Usage before and after using our adjustment model. The diagonal line shows where we expect each microsegment to be if their summary statistic aligns with what we would expect, based on our model.
From the graphs, we see that outlier microsegments tend to have a small sample size (indicated by the size of the dot), while microsegments with a large sample fall neatly in line with what our model expects. This supports our assumption that such discrepancies are predominantly due to sample size issues rather than something unique about the given microsegment. Therefore, it makes sense to adjust them in line with what the model expects, as this is likely to be what we would have observed had there been a greater sample size for that microsegment.
Deriving accurate population estimates
Having addressed the sample size issue, we then dealt with our second major problem: We did not have good estimates of the national population for each microsegment.
We could not simply use survey data by itself to obtain our population estimates, as these datasets are not weighted to provide accurate estimates of population at the fine grain that we were using for our microsegments. So, we came up with a method that started by using survey estimates, but then adjusted these estimates using credit bureau location data, as well as our own common-sense rules. We also incorporated SARS taxpayer summary data to obtain more accurate estimates at the higher income levels, which tend to be under-represented in surveys.
This combined dataset is used as part of our ENS Customer Profiling tool. There are a number of other factors that have not been addressed in this blog. These include, among others:
- Compliance, data privacy and use permissions
- Selection of datasets based on permissions and robustness
- Optimal selection of profiling data from datasets, allowing for accuracy and known bias (e.g. using Labour Force Survey not MAPS for occupation data)
- Adding more overlap variables (e.g. location) to better account for profiling data that is not well explained by the current overlap variables
- Creating a longitudinal dataset
- Maintaining a data lineage1
Read Part 2: Building a national segmentation or Part 3: Creating Location Profiles of our blog series on how we built the ENS Consumer Profiling Tool and Segmentation
1 Data lineage uncovers the life cycle of data, showing the complete data flow, from start to finish. Data lineage is the process of understanding, recording, and visualizing data as it flows from data sources to consumption. For the ENS the data lineage may change over time for subsequent datasets, therefore the development over time also needs to be maintained.